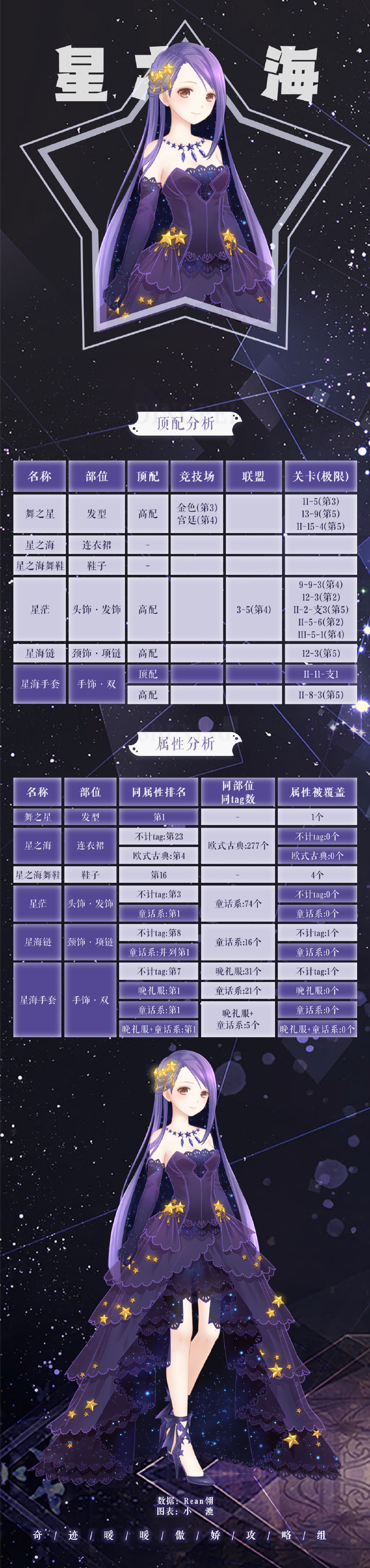
本文目录导读:
在互联网时代,信息获取的便捷性已经成为我们日常生活的一部分,小电影网站作为提供娱乐和信息的平台,吸引了大量用户的关注,由于网站数量众多,用户往往需要花费大量时间在寻找和筛选上,利用PYTHON爬虫技术来获取小电影网站的信息,成为了一种高效且实用的解决方案,本文将探讨如何使用PYTHON爬虫技术来获取小电影网站的信息。
PYTHON爬虫技术简介
PYTHON爬虫技术是一种自动化获取网页信息的程序,通过模拟浏览器行为,爬虫可以访问网站并提取所需的信息,PYTHON语言因其简单易学、功能强大等特点,成为编写爬虫的首选语言,利用PYTHON爬虫技术,我们可以轻松地从各种小电影网站上获取信息,如电影名称、演员、导演、上映时间等。
选择合适的小电影网站
在选择小电影网站时,我们需要考虑网站的可靠性、更新频率以及是否允许爬虫访问等因素,一个好的小电影网站应该具备丰富的资源、快速的更新速度以及友好的爬虫策略,我们还需要了解网站的robots.txt文件,该文件规定了爬虫访问网站的规则,避免因违反规则而导致被封禁。
编写PYTHON爬虫程序
1、确定目标URL:我们需要确定要爬取的小电影网站的URL,通过分析网站的URL结构,我们可以找到电影信息的具体位置。
2、安装必要的库:在PYTHON中,我们需要安装一些库来帮助我们编写爬虫程序,如requests库用于发送HTTP请求,BeautifulSoup库用于解析HTML页面等。
3、发送HTTP请求:使用requests库发送HTTP请求,获取小电影网站的HTML页面。
4、解析HTML页面:利用BeautifulSoup库解析HTML页面,提取我们需要的信息,我们可以使用XPath或CSS选择器来定位电影信息的具体位置。
5、数据存储:将提取到的数据存储到本地文件、数据库或其他存储介质中,以便后续分析和使用。
注意事项
1、遵守法律法规:在编写和使用PYTHON爬虫时,我们需要遵守相关法律法规和网站的规定,不得恶意攻击网站、盗取他人信息或进行其他违法行为。
2、尊重网站权益:我们需要尊重网站的权益,遵循网站的爬虫策略和robots.txt文件的规定,在获取信息时,应尽量减少对网站的负担和影响。
3、保护个人隐私:在处理从网站获取的个人信息时,我们需要保护个人隐私,不得将个人信息用于非法用途或泄露给他人。
通过PYTHON爬虫技术,我们可以轻松地从小电影网站上获取丰富的信息,在编写和使用爬虫时,我们需要遵守相关法律法规和网站的规定,尊重网站的权益和保护个人隐私,随着互联网的不断发展,PYTHON爬虫技术将更加成熟和普及,为我们的生活带来更多便利和乐趣。